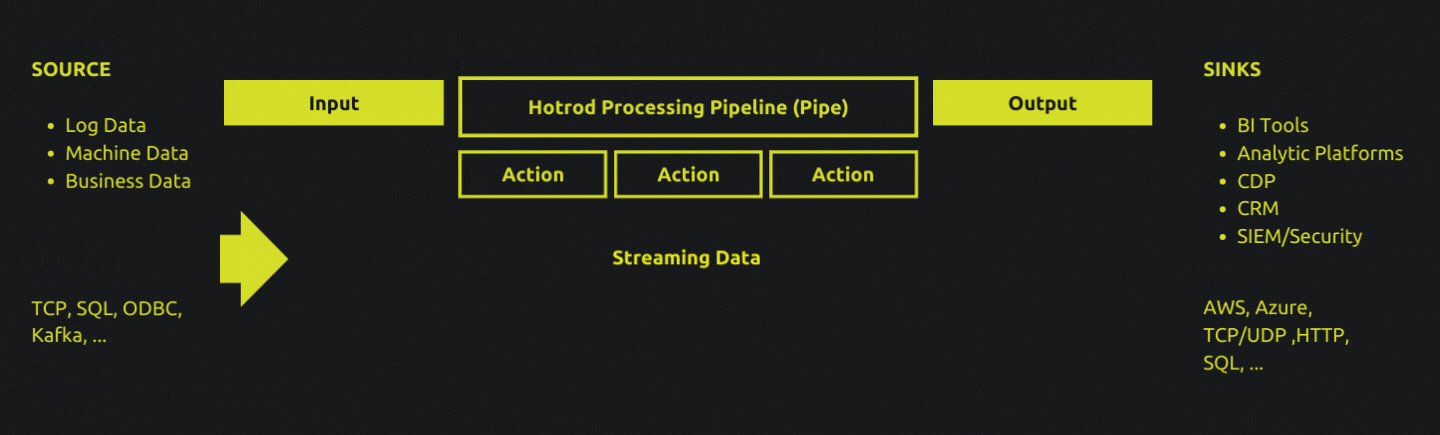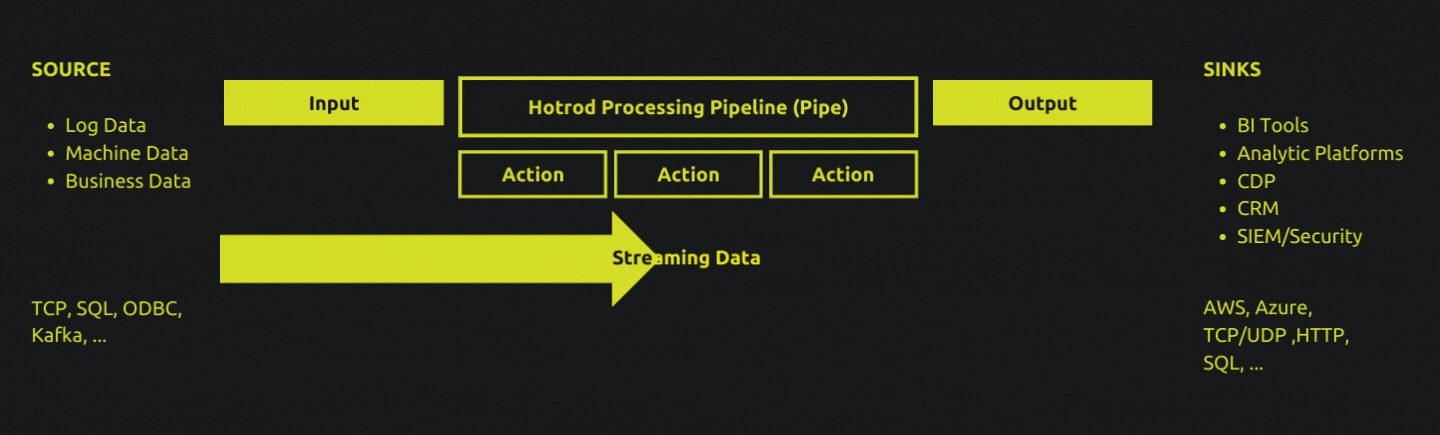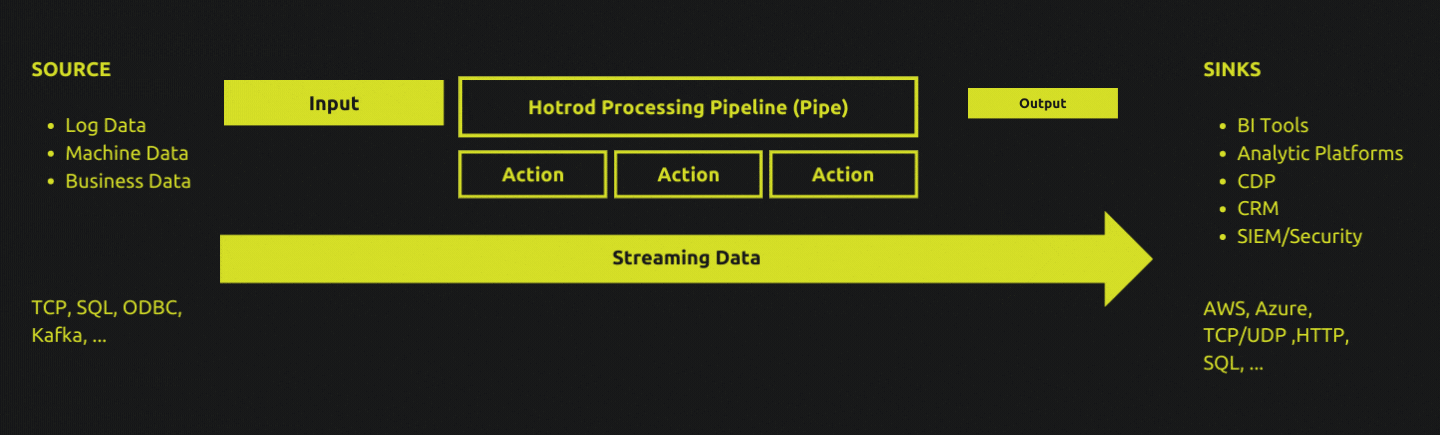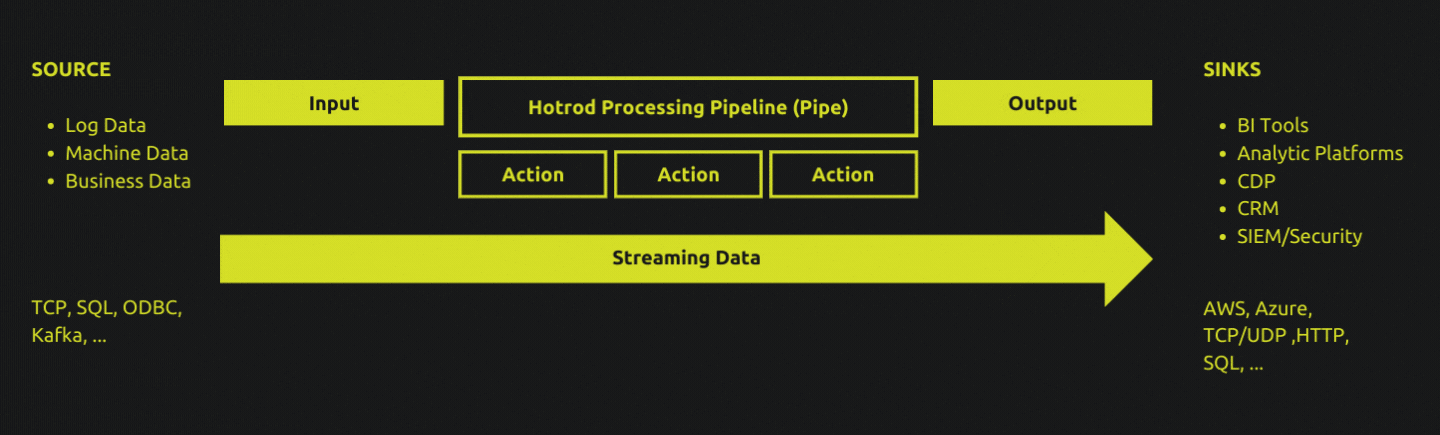
Pipes
A Pipe - or a data processing pipeline - represents a specific data processing workload, and is described with the Hotrod Pipe Language.
To make data processing more repeatable and accessible, the pipe language provides a standardized approach to defining what a particular data processing pipeline must do.
Pipes are defined in YAML format. Here's a simple pipe that makes an HTTP request, parses a JSON response, renames a field, and writes some output to a file:
name: Simple HTTP Example
input:
http-poll:
address: "http://httpbin.org/get"
raw: true
actions:
- rename:
fields:
- origin: source_ip
output:
file:
path: "/tmp/output.log"
input-field: out
All pipe definitions follow the same pattern. An input specifies where data comes from. Any number of optional actions defines the sequential transformations and manipulations on the input data. An output tells the pipe where the processed data must be delivered to.
A pipe definition is declarative: you specify what needs to happen, and leave the how it must happen part to the Hotrod runtime. In addition to data manipulation, transformation, parsing and extraction capabilities, advanced features for scheduling, batching and enrichment is also available to make dealing with streaming data simpler.
Pipe definitions are attached to one or more Hotrod Agent, which is the runtime that executes one or more pipes. Deploying pipes to agents are performed through Hotrod Server's web-based UI, it's command line interface, or it's HTTP API.
Here's another example of a pipe that executes a command on a Linux server:
name: uptime
input:
exec:
command: uptime
interval: 10s
actions:
- extract:
input-field: _raw
remove: true
pattern: 'load average: (\S+), (\S+), (\S+)'
output-fields: [m1, m5, m15]
output:
write: console
In this example, input data comes from executing the Unix uptime command every 10 seconds; the load averages (1min, 5min, 15min) are extracted using regular expressions from the input line, using the extract action. We then write the results out to the console.
So from a typical input '09:07:36 up 16 min, 1 user, load average: 0.08, 0.23, 0.31' we get a JSON record that looks like {"m1":"0.08","m5":"0.23","m15":"0.31"}.
Time series events normally have an associated time, and must be in an appropriate form to be processed and queried by data analytics systems. If our actions steps were:
- extract:
input-field: _raw
remove: true
pattern: 'load average: (\S+), (\S+), (\S+)'
output-fields: [m1, m5, m15]
- convert:
- m1: num
- m5: num
- m15: num
- time:
output-field: '@timestamp'
Then the result looks like this:
{"m1":0.08,"m5":0.23,"m15":0.31,"@timestamp":"2018-08-21T09:30:36.000Z"}
These records can then be indexed by Elasticsearch and queried with tools such as Kibana or Grafana.
So a pipe is "input -> action1 -> action2 -> ... -> output". Note that actions are optional, with the only required top-level fields being name, input, and output.
Most action steps work with JSON data. Although real-world data usually arrives as raw text, the exec input will by default 'quote' it as JSON, like {"_raw":"output line"}. The various extraction steps work on this raw data and generate sensible event fields.
Here are the available inputs and outputs, with the possible processing steps documented here.
Adding Pipes to the Hotrod System
Below, we follow the Hotrod Command Line process, to do this using the Hotrod User Interface instead, refer to our quickstart guide.
Assuming you are logged in, then:
$ hotrod agents add Joburg
agent Joburg has id e94ccdca-f379-447b-8c90-6976e77652ec
$ hotrod agents add Durban
agent Durban has id 8a1a0a29-d8f8-4098-a016-9d08f841f9a4
$ hotrod agents list
name | id | tags | pipes | last seen
-------+-------------------------------------- +------+-------+-----------
Joburg | e94ccdca-f379-447b-8c90-6976e77652ec | | |
Durban | 8a1a0a29-d8f8-4098-a016-9d08f841f9a4 | | |
Unless you explicitly specify --id with agents add, new agents will be assigned a uuid unique identifier. Agent names and ids must be unique.
A pipe definition is a file NAME.yml, where NAME is the provided name of the pipe. Pipe names must be unique, and the hotrod tool will also enforce that the name of the file matches. To enable versioning or annotation of a pipe definition, additional full stops with some text are allowed in front of the extension, for example: NAME.testing.yml or NAME.0.1.yml.
A pipe is loaded with the pipes add subcommand:
$ hotrod pipes add --file uptime.yml
$ hotrod pipes list
name
------
uptime
$ hotrod pipes show uptime
name: uptime
input:
exec:
command: uptime
interval: 2s
actions:
- extract:
input-field: _raw
remove: true
pattern: 'load average: (\S+), (\S+), (\S+)'
output-fields: [m1, m5, m15]
- convert:
- m1: num
- m5: num
- m15: num
- time:
output-field: '@timestamp'
output:
write: console
This pipe is not associated with any agent yet, so we update a particular agent:
$ hotrod agents update Joburg --add-pipe uptime
$ hotrod agents list
name | id | tags | pipes | last seen
-------+-------------------------------------- +------+--------+-----------
Joburg | e94ccdca-f379-447b-8c90-6976e77652ec | | uptime |
Durban | 8a1a0a29-d8f8-4098-a016-9d08f841f9a4 | | |
The pipe is now staged for the "Joburg" agent, and will be deployed in a short while using the configured hotrod agent.
If you do update Joburg --remove-pipe uptime then it will be removed from the staging area, and stopped by the hotrod agent.